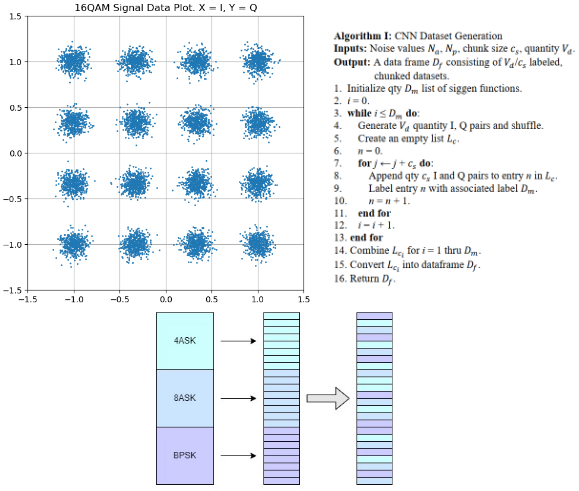
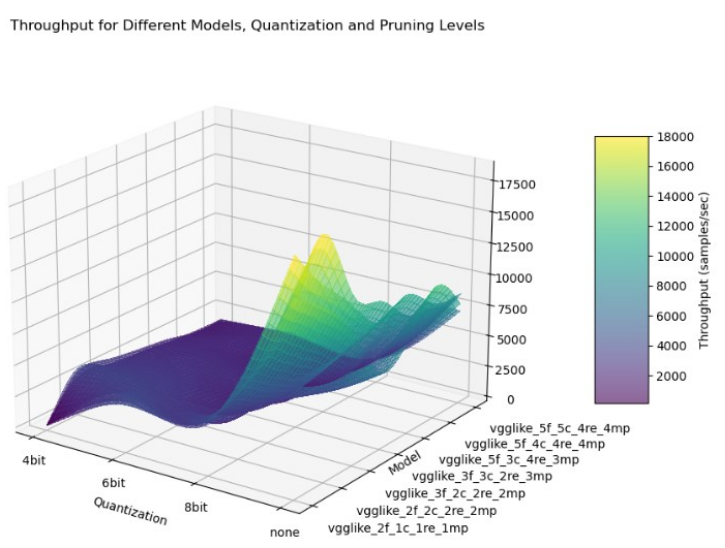
Resource and Performance Improvements of Optimized Convolutional Neural Networks for FPGA Implementations of Automatic Modulation Recognition
Joshua A. Rothe and Haya Shajaiah
In 2025 59th Annual Conference on Information Sciences and Systems (CISS), 2025
Automatic Modulation Recognition (AMR), commonly found in software defined radios, relies on speed and accuracy to effectively interpret the modulation type of incoming signals. Convolutional Neural Networks (CNNs) are growing in popularity over traditional algorithms due to their excellent performance with classification-type problems – but these are typically resource intensive, and Radio Frequency (RF) receivers are typically part of a larger system that can benefit from less resources being tied to this classification task. Field Programmable Gate Array (FPGA) implementations provide better performance than CPU and GPU implementations in most cases, and the added benefit of these functions being off the processor allows the entire system to perform better. Since resource utilization is such a critical component of effective CNN implementation, and it is often inversely tied to performance, the effectiveness of various hardware optimization techniques as well as their effects on performance should be considered by the designer. This work evaluates the tradeoffs of various model optimizations and how they affect both implementation and performance, synthesizing the models using Xilinx’s quantization-aware FINN library. In this work, a methodology is presented for the generation of I and Q signals for CNN model training and evaluation, and the performance and hardware utilization benchmarks are evaluated to determine both design considerations and effective approaches for optimizing these models for real-world implementation.